Large-Scale POMDP Planning#
Current limitation#
The ability to compute reliable and robust decisions in the presence of uncertainty is essential in robotics. Specifically, an autonomous robot must decide how to act strategically to accomplish its tasks, despite being subject to various types of errors and disturbances affecting their actuators, sensors, and perception, and despite the lack of information and understanding about itself and its environment. The errors and limited information cause the effects of performing actions to be non-deterministic from the robot’s point of view and cause the robot’s state to only be partially observable, which means the robot never knows its exact state.
Many good approximate POMDP (Partially Observable Markov Decision Process) solvers have been proposed since mid 2000, allowing POMDP to generate good strategies for realistic problems. Despite these advances, solving problems with large discrete action spaces remains difficult. This project aims to reduce such difficulties. To this end, we develop an adaptive method for action selection based on quantile statistics, specifically Cross-Entropy methods for optimization.
A novel solver: QBASE#
We first propose a method, called Crossed-Entropy-based Multi Armed Bandit (CEMAB) [1], for Multi-arm bandit problem –a framework used for action selection in many good online POMDP solvers today. Numerical experiments with up to 10,000 arm indicates that CEMAB outperforms various existing MAB methods, including ε-greedy, softmax, EXP1, UCB1.
We then propose an expansion of CEMAB to approximately solve POMDP problems on-line, and call this solver Quantile-Based Action SElecter (QBASE) [2]. Experiments on multiple benchmark, multi-robot problems and partially observed inventory control problems [3] with up to 1M actions indicate that QBASE can generate good policies for problems with large discrete action space within reasonable time.
Example: Navigation, and Target Finding#
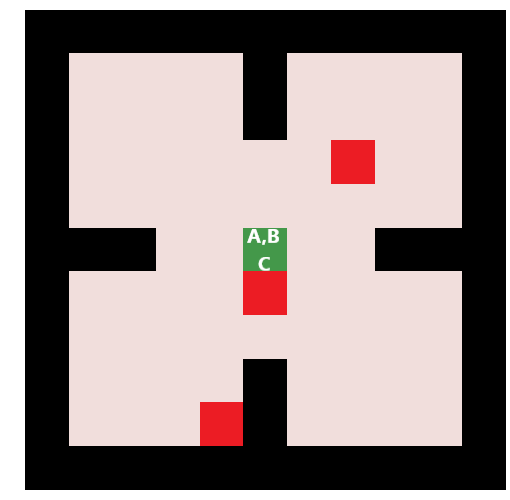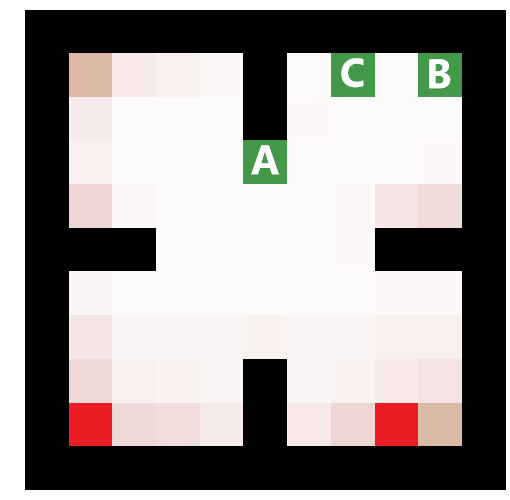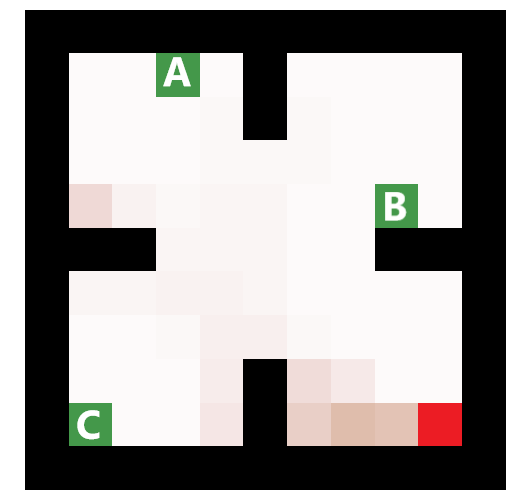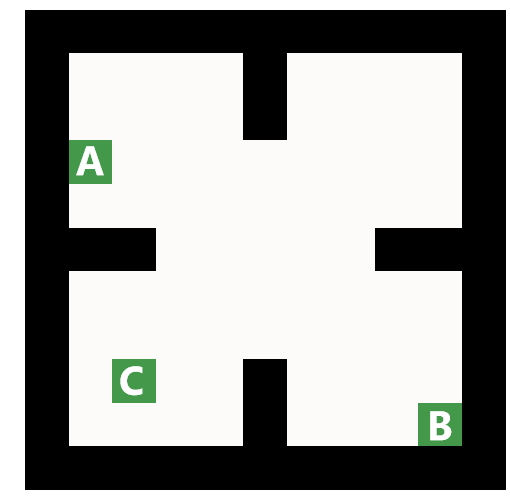
An example of QBASE applied to multi-agent multi-target finding with centralized control.
Left: A visualization of a policy for an agent navigating in 2D grid world. The agent can only perceive the observation by touching it nearby cells. Even though the observation function is perfect. However, since multiple states can generate the exact same observation, this scenario is partially observable.
Right: A visualization of a policy for the case of 3 agents finding 3 targets. The agents are green squares marked with letters. The actual positions of the targets before being captured are marked with dark red. The pink color indicates the agents’ belief that a target is at the particular cell, the darker the color the higher the probability.

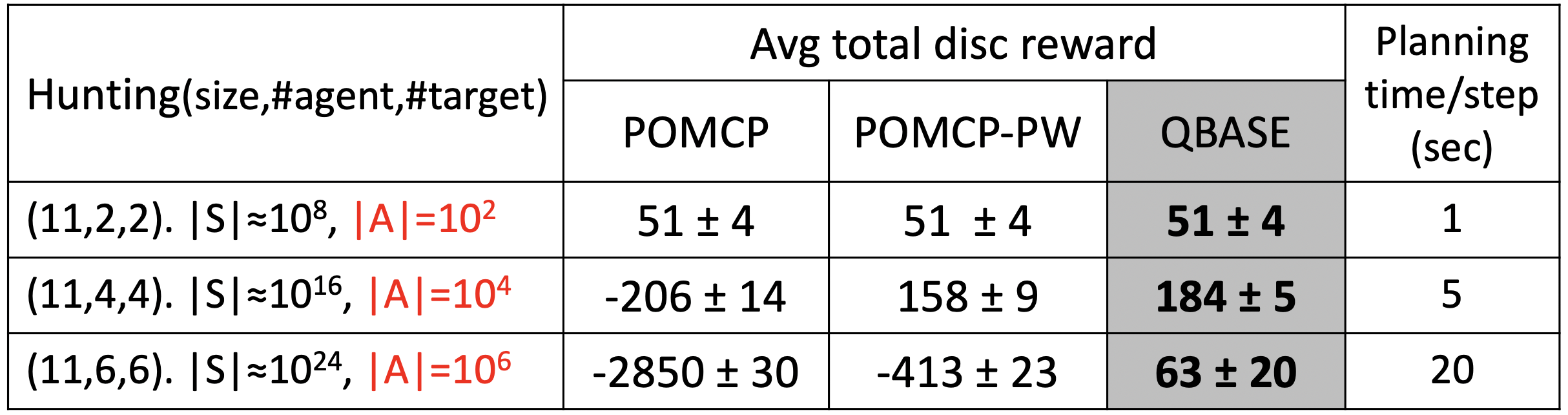
Performance on different numbers of agents and targets. The notation |S| is the size of the state space, while |A| is the size of the action space.
Reference
Erli Wang and Hanna Kurniawati and Dirk Kroese. CEMAB: A Cross-Entropy-based Method for Large-Scale Multi-Armed Bandits. Proc. Australasian Conference on Artificial Life and Computational Intelligence (ACALCI). 2017. (pdf)
Erli Wang and Hanna Kurniawati and Dirk Kroese. An On-line Planner for POMDPs with Large Discrete Action Space: A Quantile-Based Approach. Proc. Int. Conference on Automated Planning and Scheduling (ICAPS). 2018. (pdf,)