Counterfactual-based Data Augmentation for Control#
Issue of data shortage#
The shortage of sufficient interaction data challenge the practicality of decision making method in reality. For example, medical data are often collected from different hospitals, causing domain shift issues. There are also some examples that the training data are not known in advance, such as the demand forecasting of new products.
To address this issue, various of methods have been proposed. For instance, domain randomization aims to train the model among diverse scenarios, so that the agent can learn a policy that could be resilient to similar variations. However, our pre-experiment shows that in sequential decision-making tasks, the algorithm is senstive to small changes from domain shift, leading a significant decrease in the performance. Many of data augmentation technique improve the data diversity by manipulating the empricial dataset. However, the augmented data really matters are the ones reachable from current state or action. This is because the goodness of action depends on a sequential estimate of future state and actions.
Why MLP does not work#
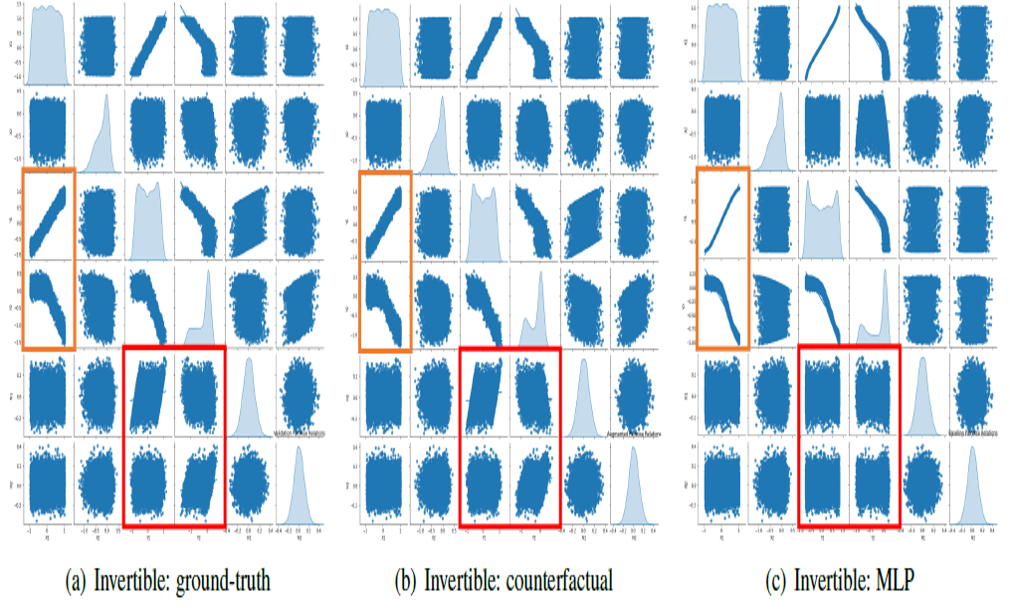
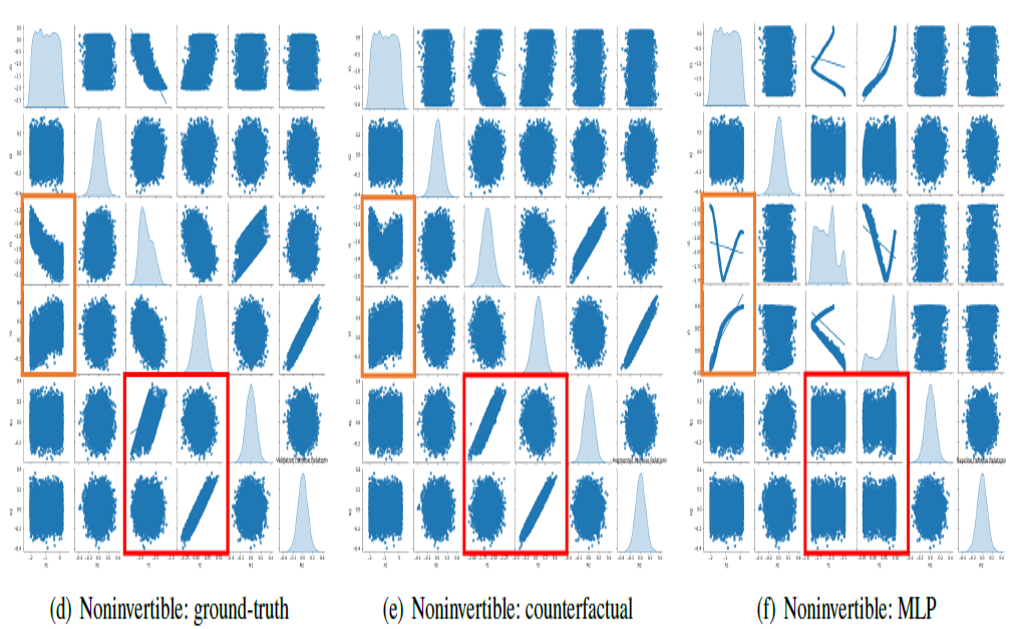
In invertible cases, we see both MLP-based methods and our method show potential for recovering ground truth dynamics to some extent. However, the presence of heterogeneity in the distribution destroys the invertibility, posing significant challenges for traditional MLP methods. Inspired by (Tank et al. TPAMI’2020), we construct individual neural networks for each element in \(s_{t+1}\) with \(\lambda\).
Our novel framework: ACAMDA#
When solving sequential decision problems, the solution space for a particular task is often smaller than the original space. In this work, we realized the data augmentation in reinforcement learning domain essentially is to intervene the Bayesian network under different noise circumstances, sometimes called counterfactual inference. Such inference is exactly based on the same condition for particular individuals rather than simulating a different action at the population level. Therefore, our idea is motivated by the observation that a high-quality generative model often requires two closely related causality tasks:
discover a graphical structure to adjust the confounding bias and,
simulate the effect of a change within a system even if that change never happened in reality.
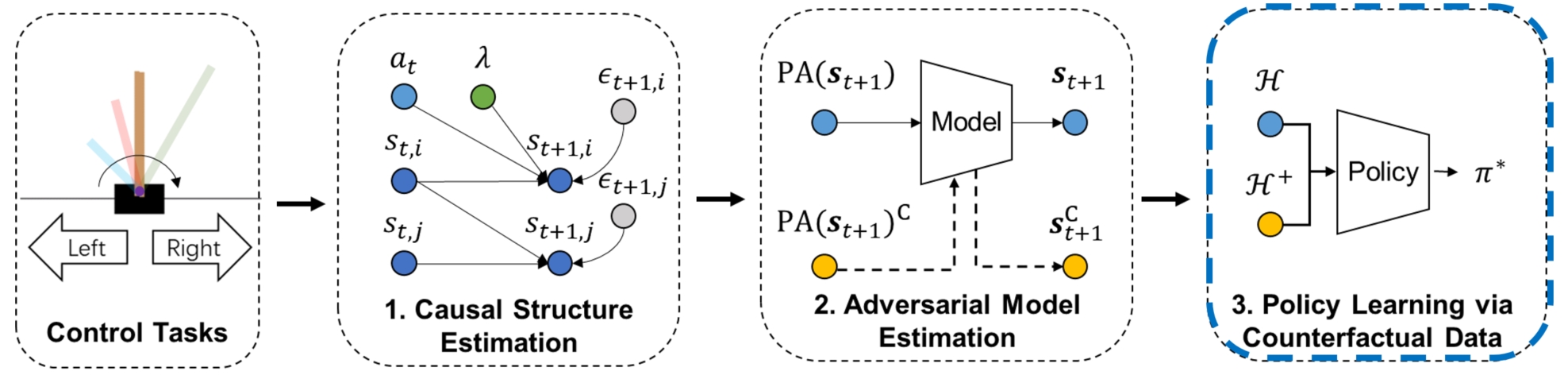
ACAMDA combines causal recovery with guided counterfactual data augmentation to realize sequential decision-making across heterogeneous environments in a data-driven manner, so that non-expert datasets can be used to disentangle the causal mechanism, leading to tremendous cost savings in collecting data from multiple sources. Experiments on the synthetic dataset, control tasks, and inventory management over extensive variants show promising performance.
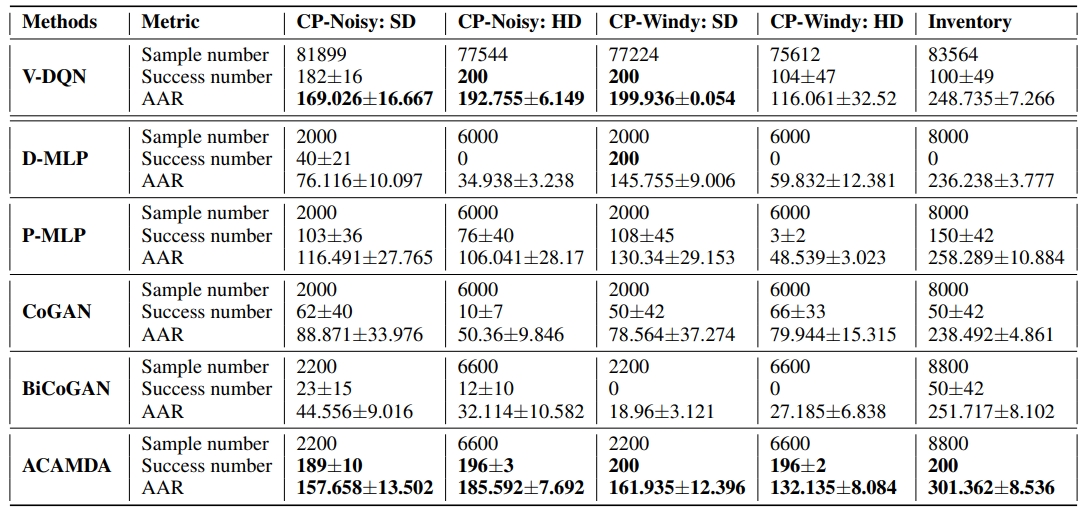
In short, ACAMDA has shown that the proposed method achieves comparable results to other leading model-based approaches when the testing domain is identical to the training domain. The improving performance becomes clear and significant when the policy adapts to novel unseen scenarios. We believe the significance of this work rooted in its ability to incorporate of future work to create social values, not only developing framework. For example, inventory control for new products when there is no data in advanced.
Reference
Sun, Yuewen, Erli Wang*, Biwei Huang, Chaochao Lu, Lu Feng, Changyin Sun, and Kun Zhang. “ACAMDA: Improving Data Efficiency in Reinforcement Learning through Guided Counterfactual Data Augmentation”. Proceedings of the AAAI Conference on Artificial Intelligence, 38(14), 15193-15201. (pdf)
US20230214694 patent. (pdf)